КАНАЛ
в теории информации, всякое устройство, предназначенное
для передачи информации. В отличие от техники, информации теория отвлекается
от конкретной природы этих устройств, подобно тому как геометрия изучает
объёмы тел, отвлекаясь от материала, из к-рого они изготовлены (ср. Канал
информационный).
Различные конкретные системы связи рассматриваются в теории информации
только с точки зрения количества информации, к-рое может быть надёжно
передано с их помощью. T. о. приходят к понятию К.: канал задаётся множеством
"допустимых" сообщений (или сигналов)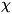 на
на
входе, множеством сообщений (сигналов) у на выходе и набором условных
вероятностей (у\х) получения
(у\х) получения
сигнала у на выходе при входном сигнале х. Условные вероятности
(у\х) описывают статистич. свойства "шумов" (помех), искажающих сигналы
в процессе передачи. В случае, когда
(у\х) = 1 при у = и
(у\х) = = О при у <> х, К. наз. каналом без "шумов". В соответствии
со структурой входных и выходных сигналов выделяют К. дискретные и К. непрерывные.
В дискретных К. сигналы на входе и на выходе представляют собой последовательности
"букв" из одного и того же или различных "алфавитов" (см. Код). В
непрерывных К. входной и выходной сигналы суть функции непрерывного параметра
t
- времени. Возможны также смешанные случаи, но обычно в качестве идеализации
предпочитают рассматривать один из указанных двух случаев.
Способность К. передавать информацию характеризуется нек-рым числом
- пропускной способностью, или ёмкостью, К., к-рое определяется как максимальное
количество информации относительно сигнала на входе, содержащееся в сигнале
на выходе (в расчёте на единицу времени).
Точнее: пусть входной сигнал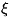 принимает
принимает
нек-рые значения х с вероятностями
(х). Тогда по формулам теории вероятностей можно рассчитать как вероятности
q
(у) того, что сигнал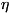 на выходе
на выходе
примет значение у: так и вероятности
(, у) совмещения событий
= x, = у:
P(X, у) = р(х) р(у\х).
По этим последним вычисляется количество информации (в двоичных единицах)
I(,) =
I(,) и
его среднее значение
![]()
![]()
где 1 - длительность. .верхняя
граница С величин R, взятая по всем допустимым сигналам на
входе, наз. ёмкостью К. Вычисление ёмкости, подобно вычислению энтропии,
легче
в дискретном случае и значительно сложнее в непрерывном, где оно основывается
на теории стационарных случайных процессов.
Проще всего положение в случае дискретного К. без "шумов". В теории
информации устанавливается, что в этом случае общее определение ёмкости
С равносильно следующему:
![]()
где N(T) - число допустимых сигналов длительностью T.
Пример 1. Пусть "алфавит" К. без "шумов" состоит из двух "букв"-0 и
1, длительностью сек каждая.
сек каждая.
Допустимые сигналы длительностью T = n
представляются последовательностями символов 0 и 1. Их число N (T) =
2n. Соответственно

Пример 2. Пусть символы О и 1 имеют длительность
и 2 сек соответственно. Здесь допустимых
сигналов длительностью T = т будет меньше, чем в примере
1. Так, при n = 3 их будет всего 3 (вместо 8). Можно подсчитать
теперь

При необходимости передачи записанных с помощью нек-рого кода сообщений
по данному К. приходится преобразовывать эти сообщения в допустимые сигналы
К., т. е. производить надлежащее кодирование. После передачи надо
произвести операцию декодирования, т. е. операцию обратного преобразования
сигнала в сообщение. Естественно, что кодирование целесообразно производить
так, чтобы среднее время, затрачиваемое на передачу, было возможно меньше.
При одинаковой длительности символов на входе К. это означает, что надо
выбирать наиболее экономный код с "алфавитом", совпадающим с входным "алфавитом"
К.
При описанной процедуре "согласования" источника с К. возникает специфич.
явление задержки (запаздывания), к-рое может пояснить следующий пример.
Пример 3. Пусть источник сообщений посылает через промежутки времени
Специально в отношении примера 3 уместно добавить следующее. Для рассматриваемых
Утверждение "основной теоремы" (с заменой безошибочной передачи на "почти
длиной 1/v (т. е. со скоростью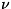 )
)
независимые
символы, принимающие значения x
1/8. Пусть К. без "шумов" такой же, как в примере 1, и кодирование осуществляется
мгновенно. Полученный сигнал или передаётся по К., если последний свободен,
или ожидает (помещается в "память") до тех пор, пока К. не освободится.
Если теперь выбран, напр., код x
х
01, X
<=1/2(т. е. 1/>=2),
то
за время между появлением двух последовательных значений х кодовое
обозначение успевает передаться и К. освобождается. T. о., здесь между
появлением к.-л. "буквы" сообщения и передачей её кодового обозначения
по К. проходит промежуток времени 2т. Иная картина наблюдается при>1/2;n- "буква"
"буква"
сообщения появляется в момент (п - 1)/и
её кодовое обозначение будет передано по К. в момент 2n.
Следовательно,
промежуток времени между появлением ге-й "буквы" сообщения и моментом её
получения после декодирования переданного сигнала будет больше, чем n(2t
- 1lv), что стремится к бесконечности при n->°°. Таким образом,
в этом случае передача будет вестись с неограниченным запаздыванием. Стало
быть, для возможности передачи без неограниченного запаздывания при данном
коде необходимо и достаточно выполнение неравенства<=1/2.
Выбором более удачного кода можно увеличить скорость передачи, сделав её
сколь угодно близкой к ёмкости К., но эту последнюю границу невозможно
превзойти (разумеется, сохраняя требование ограниченности запаздывания).
Сформулированное утверждение имеет совершенно общий характер и наз. основной
теоремой о К. без "шумов".
сообщений двоичный код x
Из-за различной длины кодовых обозначений время W
для n-й "буквы" первоначального сообщения будет случайной величиной. При
< 1/(1/
- ёмкость К.) и n -> oo его среднее значение приближается к нек-ро-му
пределу т(), зависящему от.
С приближением к критич.
значению 1/ значение т()
растёт
пропорционально (.-1 -)-1.
Это
опять-таки отражает общее положение: стремление сделать скорость передачи
возможно ближе к максимальной сопровождается возрастанием времени запаздывания
и необходимого объёма "памяти" кодирующего устройства.
безошибочную") справедливо и для К. с "шумами". Этот факт, по существу
основной для всей теории передачи информации, наз. теоремой Шеннона (см.
Шеннона
теорема). Возможность уменьшения вероятности ошибочной передачи через
К. с "шумами" достигается применением т. н. помехоустойчивых кодов. Пример
4. Пусть входной "алфавит" К. состоит из двух символов О и 1 и действие
"шумов" сводится к тому, что каждый из этих символов при передаче может
с небольшой (напр., равной 1/10) вероятностью p перейти в другой
или с вероятностью q = 1 - p остаться неискажённым. Применение помехоустойчивого
кода сводится, по сути дела, к выбору нового "алфавита" на входе К. Его
"буквами" являются к-членные цепочки символов 0 и 1, отличающиеся одна
от другой достаточным числом D знаков. Так, при n = 5 и D
= 3 новыми "буквами" могут быть 00000, 01110, 10101, 11011. Если вероятность
более чем одной ошибки на группу из пяти знаков мала, то даже искажённые
эти новые "буквы" почти не перепутываются. Напр., если получен сигнал 10001,
то он почти наверное возник из 10101. Оказывается, что при надлежащем подборе
достаточно больших n и D такой способ значительно эффективнее
простого повторения (т. е. использования "алфавитов" типа 000, 111). Однако
возможное на этом пути улучшение процесса передачи неизбежно сопряжено
с сильно возрастающей сложностью кодирующих и декодирующих устройств. Напр.,
подсчитано, что если первоначально
= 10-2 и требуется уменьшить это значение до p
10-4, то следует выбирать длину n кодовой цепочки не
менее 25 (или 380) в зависимости от того, желают ли использовать ёмкость
К. на 53% (или на 80% ). Лит. см. при ст. Информации теория.
Ю. В. Прохоров.
А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я